TLD;DR: I implemented a refinement network to upscale Howard’s 480p outputs to 1080p; based closely on the method proposed by Sengupta, et. al.
Hi! I’m Kai. If you’re new here, here’s the rundown:
- I’m building a neural network based on this paper that removes the background from videos.
- Given a video of a person, and a video of the background, the goal is for the network to output a video of the person “cut out” from the background.
- The neural network is affectionately dubbed “Howard”.
Last week, I got to the point where Howard was outputting low-resolution images called alpha matttes. These mattes serve as a guide for how transparent every pixel of the final output should be. Let’s take this image as an example:

A perfect alpha matte for this image would look like this:

As you can see, the image is solid white for areas that should be 100% opaque, like the person’s nose, solid black for bits of the background that need to be cut out, and somewhere in between for wispy details like hair.
Now, let’s compare the perfect matte above to one which Howard produced (not using the same input image as above, but the point still stands):
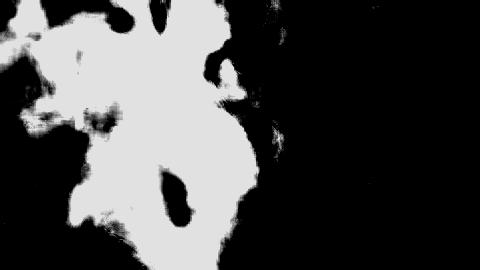
It’s… lackluster. There are lots of ways Howard’s outputs could be made better, but this past week, I decided to focus on one in particular: resolution. The inputs to Howard are 1080p frames of video, but at the beginning of this week, Howard’s outputs were limited to 480p.

Enter the refinement network. The refinement network first upsamples the low-resolution output from Howard’s first half, then takes little tiny square patches, each only 4 by 4 pixels, and refines them. The result of this refinement can be seen below:
Original 480p output:

Refined 1080p output:

So… it’s still a weird blob, but at least it’s in full, glorious 1080p.
Now, the way this refinement network (as proposed in the paper) works is actually quite clever. The main idea is that refining every single 4x4 patch of a 1080p image would be way too much unnecessary work.
This is because alpha mattes are mostly made up of solid white and solid black regions that can be upscaled or downscaled arbitrarily without loss of quality – that is to say, a blurry solid white patch is the same as a sharp solid white patch, because they’re both still just solid white.
So, what Sengupta and his team do to reduce unnecessary computation is make Howard generate not just a coarse 480p alpha matte, but also an image called an error map.

Basically, the brighter the pixel is in the error map, the less confident Howard is saying he is about his results for that area of the image. This is useful to us, because it means we can use the error map to tell the refinement network where to focus its attention! By not having the refinement network waste time refining the solid white or solid black areas, we get our 1080p result nice and crisp while using a fraction of the computation power and system memory to pull it off.
I’m not sure if I ever would have come up with something like this on my own! It’s a super clever technique, and it’s only one of many things I’ve… uh… academically borrowed from Sengupta and his team’s research paper :)
Conclusion
This post is a brief one, but I hope you enjoyed seeing the progress Howard made this week. On the agenda for the coming week, I have plans to work on the system Howard will use to actually accept and ingest video files (so far he’s only ever tried training data). Look out for a post next week regarding the pain I go through as I try to get feature matching and homography solving working!
Thanks for reading,
Kai