It’s been over 7 weeks since my last post on this blog. Since then, a lot has changed. This is meant to be a short summary of what’s happened.
First and foremost, I made an important decision regarding the project. Up until about a week or two ago, I was still hoping to implement my own version of the network proposed by Sengupta, et. al. in the all-important paper that this madness is all based on. I realized my reasons for wanting to train my own version of it were no longer valid. When I began this project six months ago, I was still exceptionally brand-new to ML and PyTorch, and so implementing my own version of Sengupta’s architecture was primarily meant as a learning exercise. I dedicated a ton of time and effort to it, and learned a lot from doing it, but I now feel that I don’t have much more to gain from it. I was never able to get my version of their architecture to perform up-to-spec, anyways.
Thus, from now on, the matting part of the project will be handled using pre-trained weights made available under the MIT license by Sengupta and his team at the University of Washington. Personally, I am glad that I’ve been able to swallow my pride and acknowledge that the best way forward for this project is to not try to do everything myself. Instead, I need to be focusing on only the parts of the project that haven’t already been cracked, and it turns out there’s still a lot of problems that need solving.
So, what am I actually working on these days? Well, to put it briefly: lining up images automatically. Turns out it’s a really hard problem in this particular context, and I’ve already implemented and tested several architectures and solutions to try to get it working. Most recently, I’ve been diving into deep homography estimation. We’ll see if that actually bears any fruit. This coming week, I plan to look into recurrent homography estimation, and then if that doesn’t work, probably recurrent TPS transform estimation. We’ll see.
There’s a lot up in the air right now, but rest assured I am still consistently chipping away at this problem and having fun while doing it. I genuinely believe that I can get this system working, but it’s going to take some work.
TL;DR: This week, I wrote the logic for processing real user-given input videos and completely rewrote the first half of the network, and have gotten some amazing results!
Hi, I’m Kai. If you’re new here, let me catch you up to speed:
I’m building a neural network which removes the background from videos of people.
It’s based off of this paper by Soumyadip Sengupta and his team at the University of Washington.
The neural network is named Howard, but if you really like, you can call him Howie.
The way this network functions is simple – it takes two videos as input: one of a person in some environment, and one of just the environment. As long as the camera motion is similar in both shots, the network will output an image sequence where the person has been “cut out” from the environment. If you’ve ever used Zoom’s virtual background feature, it’s like that – but better.
Seasoned Experts vs. One Inexperienced Boi
A week ago, I had just barely gotten a janky, low-quality version of Howard to fully work for the first time. I wrote about it here.
The reason Howard wasn’t working very well is because I have pride issues – by which I mean instead of just implementing the proven algorithm from the academic paper written by folks way smarter than me, I thought to myself “ooh, what if I just tried to come up with my own original architecture? What could go wrong?”
Turns out that in a battle of wits between a teenager with no experience whatsoever and seasoned field experts, the experts tend to win.
This week, I finally just decided to bin my old, terrible architecture and exactly replicate the architecture in Sengupta et. al.‘s paper. And guess what! It works spectacularly!
Here’s how my old architecture faired on some test videos:
Aaand here’s how the new, expert-designed architecture does on those same test videos:
Spot the difference, I dare you.
Making Howard Almost Useable
I’d like to talk about how those videos were actually made, because that was the other thing I did this week.
Up until this week, Howard had only ever tried to operate on fake, synthesized training data. Training data is special since it contatins not just an example of an input Howard might see, but also an example of what the correct output for that input is. This means that Howard can learn from his mistakes while operating on the training data.
In a real use case, though, Howard won’t have the right answer – he’ll just have two video files given to him by a user, and he’ll have to make his best guess at what the right way to cut the subject out is.
So, you say, just feed those videos to him and see what he spits out! Well, that doesn’t quite work for one big reason:
The two user-generated videos very likely have significantly different camera translation, rotation and clip length.
This is a problem because it means that the “naive solution” of just taking frame X from the subject video and frame X from the background video and having Howard crunch them doesn’t work at all.
In machine learning, there’s a concept called the train/test domain gap. The idea is that for many problems worth solving with ML, the data you’d feed to the neural network in a real-world usecase and the data you have available to train that network on come from different statistical distributions. In my case, that turns out to correspond to the fact that there doesn’t really exist a large, accessible dataset of moving camera videos of people standing in their natural environment, videos of just that environment, and videos of the people cut out from their environment. I’d be really happy if that kind of dataset did exist, but it doesn’t, so I have to settle for the next-best thing: synthesized training data.
The data that I actually train Howard on is similar to the ideal data, but still part of a very different distribution – for example, the background behind the person and the background that is fed to the network are only ever so slightly misaligned, whereas in real use-cases, those two would be very likely not aligned hardly at all.
So if I can’t make the training data have the same statistical distribution as the real-world use-case data, then I need a way to do the opposite – make the real-world use-case data have as close of a distribution to the training data as I can. Following the advice of Mr. Sengupta, who kindly provided me with some very useful resources and pointers after I emailed him, I’m accomplishing this by using homographies.
A homography (in the context of this project) is a kind of transformation you can apply to an image. Specifically, it’s a transformation that warps the perspective, translation, rotation, and scale of a given query image such that it aligns with a given test image. This is very handy because it means I can warp the user-given background frames to match more closely with the user-given foreground frames, thus significantly closing the domain gap between the real-world and train data!
To sum it all up, here’s what Howard actually does when I give him a pair of real-world videos I want him to process:
For every source frame from the video of the person in their environment…
…Howard:
Grabs a few background frames that are temporally nearby from the video of just the environment (one example is pictured):
Detects hundreds of unique features in each background frame
Matches those features with features detected in the source frame:
Applies a homography transformation to line up the matched sets of features as close as possible
Picks the background frame from the set that aligns the closest with the source frame after being warped:
Feeds the source frame and the selected warped background frame to Howard, who processes them and outputs the result as an image with an alpha channel.
This results in a sequence of RGBA PNG files being output to a directory, which I can then use in any modern compositing software however I like!
Conclusion
This week was great! Even though I made a ton of progress, I still have a long ways to go before Howard is ready to be shared fully with the world. That said, I’m totally excited for the next couple of weeks of work, because I do feel like I’m nearing the finish line.
Thanks for reading,
Kai
P.S. – The most fun part of all of this actually turns out frequently to be what sort of craziness Howard outputs when I accidentally break him! Here are some of my favorite psychedelic art pieces I inadvertently caused him to make:
TLD;DR: I implemented a refinement network to upscale Howard’s 480p outputs to 1080p; based closely on the method proposed by Sengupta, et. al.
Hi! I’m Kai. If you’re new here, here’s the rundown:
I’m building a neural network based on this paper that removes the background from videos.
Given a video of a person, and a video of the background, the goal is for the network to output a video of the person “cut out” from the background.
The neural network is affectionately dubbed “Howard”.
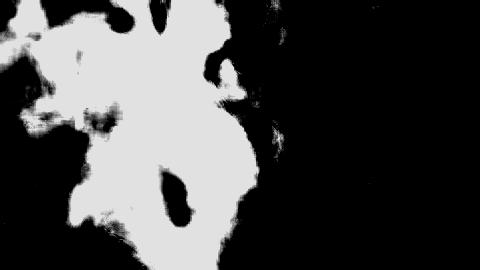
Last week, I got to the point where Howard was outputting low-resolution images called alpha matttes. These mattes serve as a guide for how transparent every pixel of the final output should be. Let’s take this image as an example:
A perfect alpha matte for this image would look like this:
As you can see, the image is solid white for areas that should be 100% opaque, like the person’s nose, solid black for bits of the background that need to be cut out, and somewhere in between for wispy details like hair.
Now, let’s compare the perfect matte above to one which Howard produced (not using the same input image as above, but the point still stands):
It’s… lackluster. There are lots of ways Howard’s outputs could be made better, but this past week, I decided to focus on one in particular: resolution. The inputs to Howard are 1080p frames of video, but at the beginning of this week, Howard’s outputs were limited to 480p.
Enter the refinement network. The refinement network first upsamples the low-resolution output from Howard’s first half, then takes little tiny square patches, each only 4 by 4 pixels, and refines them. The result of this refinement can be seen below:
Original 480p output:
Refined 1080p output:
So… it’s still a weird blob, but at least it’s in full, glorious 1080p.
Now, the way this refinement network (as proposed in the paper) works is actually quite clever. The main idea is that refining every single 4x4 patch of a 1080p image would be way too much unnecessary work.
This is because alpha mattes are mostly made up of solid white and solid black regions that can be upscaled or downscaled arbitrarily without loss of quality – that is to say, a blurry solid white patch is the same as a sharp solid white patch, because they’re both still just solid white.
So, what Sengupta and his team do to reduce unnecessary computation is make Howard generate not just a coarse 480p alpha matte, but also an image called an error map.
Basically, the brighter the pixel is in the error map, the less confident Howard is saying he is about his results for that area of the image. This is useful to us, because it means we can use the error map to tell the refinement network where to focus its attention! By not having the refinement network waste time refining the solid white or solid black areas, we get our 1080p result nice and crisp while using a fraction of the computation power and system memory to pull it off.
I’m not sure if I ever would have come up with something like this on my own! It’s a super clever technique, and it’s only one of many things I’ve… uh… academically borrowed from Sengupta and his team’s research paper :)
Conclusion
This post is a brief one, but I hope you enjoyed seeing the progress Howard made this week. On the agenda for the coming week, I have plans to work on the system Howard will use to actually accept and ingest video files (so far he’s only ever tried training data). Look out for a post next week regarding the pain I go through as I try to get feature matching and homography solving working!